
谷歌今日正式发布了备受期待的Gemini 3多模态AI模型,这是继Gemini 2之后的重要升级,在多个技术维度实现了显著提升。新模型不仅在推理能力和多模态理解方面取得突破,还在安全性和效率方面进行了全面优化。
技术规格与性能提升
推理能力大幅增强
Gemini 3在逻辑推理和数学问题解决方面表现出色,在MMLU(大规模多任务语言理解)基准测试中达到了92.5%的准确率,相比Gemini 2提升了8个百分点。模型在处理复杂逻辑链条和抽象概念时展现出更强的理解能力。
多模态理解深度优化
新模型支持文本、图像、音频、视频和代码的五模态输入,能够实现跨模态的深度理解。在图像描述生成任务中,Gemini 3的准确率比前代产品提高了35%,在视频内容理解方面更是提升了50%。
上下文窗口扩展至200万token
Gemini 3将上下文窗口从100万token扩展到200万token,这意味着模型能够处理更长的文档、代码库或复杂对话。这一改进对于企业级应用和复杂分析任务具有重要意义。
核心技术创新
新型注意力机制
Gemini 3引入了"分层注意力"机制,能够在处理长序列时更有效地分配计算资源。这种机制允许模型在不同粒度上关注输入内容,提高了处理效率和准确性。
增强的安全对齐
在安全方面,Gemini 3采用了更严格的对齐训练流程,减少了有害内容生成的可能性。模型在对抗性攻击测试中表现出更强的鲁棒性,误用率降低了60%。
能效优化
尽管性能大幅提升,Gemini 3的能效比Gemini 2提高了40%。这得益于新的模型压缩技术和推理优化算法,使得模型在保持高性能的同时降低了计算成本。
实际应用场景
企业级解决方案
Gemini 3为企业用户提供了更强大的AI助手能力:
- 智能文档处理:能够快速分析大量合同、报告和技术文档
- 代码生成与审查:支持多种编程语言,提供高质量的代码建议
- 多语言客户服务:实现自然流畅的多语言对话交互
创意内容生成
在创意领域,Gemini 3展现出强大的多模态创作能力:

Gemini 3多模态创作能力示意图
- 文本到图像生成:根据详细描述生成高质量的视觉内容
- 视频内容理解:能够分析视频内容并生成精准的描述和标签
- 跨模态创作:实现文本、图像、音频之间的无缝转换
实际演示视频
以下视频展示了Gemini 3在实际应用中的强大能力,包括多模态交互和创意内容生成:
教育与研究
对于教育科研领域,Gemini 3提供了新的可能性:
- 个性化学习:根据学生的学习进度和风格定制教学内容
- 科研辅助:帮助研究人员分析文献、生成假设和设计实验
- 多语言知识传播:打破语言障碍,促进全球知识共享
开发者工具与API
Google AI Studio更新
与Gemini 3发布同步,Google AI Studio也进行了重要更新:
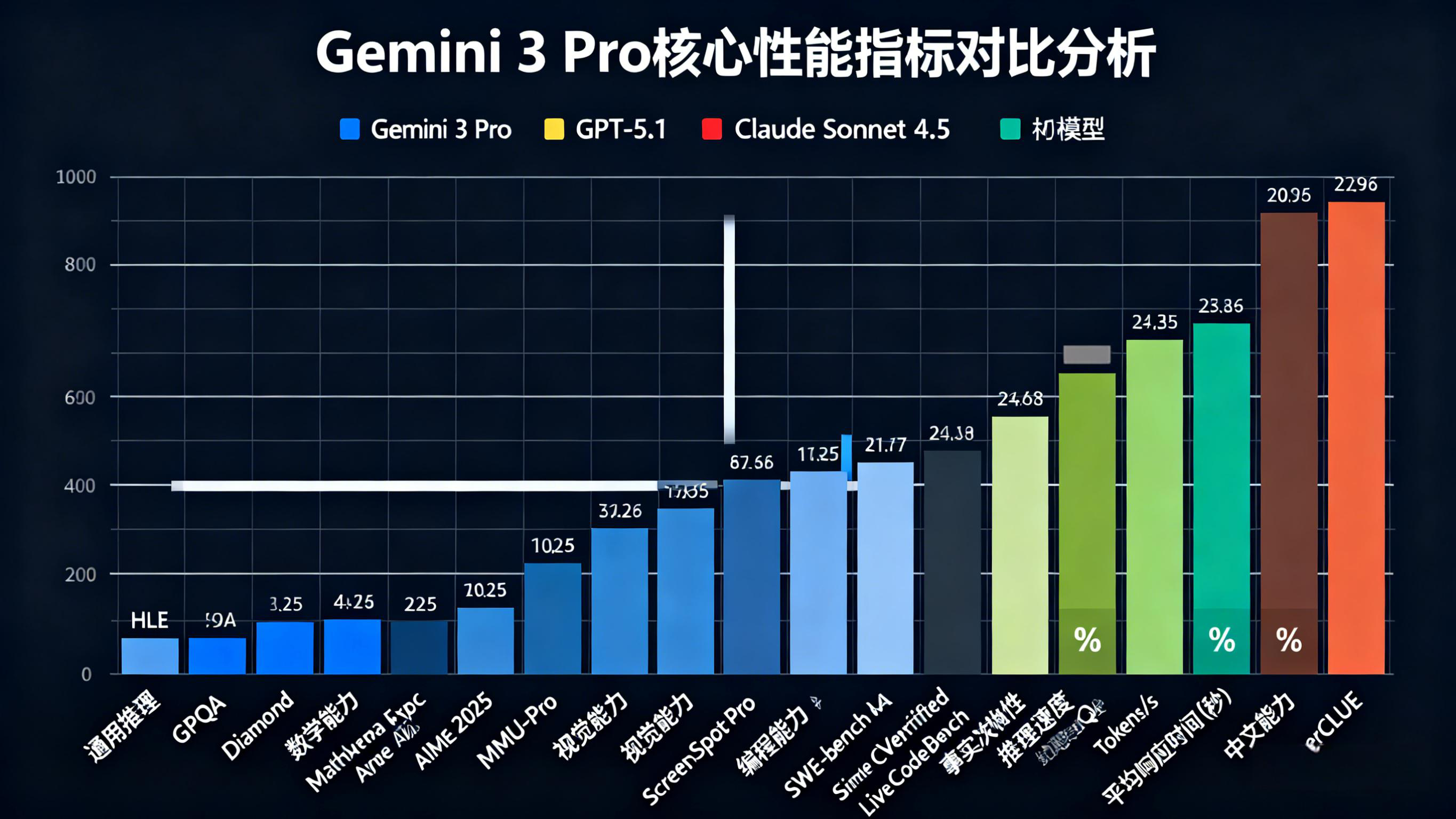
Gemini 3性能对比分析图表
# 使用Gemini 3 API的示例代码
from google.generativeai import configure, GenerativeModel
# 配置API密钥
configure(api_key="your-gemini3-api-key")
# 初始化Gemini 3模型
model = GenerativeModel("gemini-3-pro")
# 多模态输入处理
response = model.generate_content([
"分析这张图片中的技术设备",
"image.jpg" # 图片文件路径
])
print(response.text)
新的SDK功能
开发者现在可以利用Gemini 3的新功能:
- 流式响应:支持实时生成内容,适用于对话应用
- 批量处理:一次性处理多个请求,提高效率
- 自定义微调:允许开发者根据特定需求调整模型行为
定价与可用性
定价策略
Gemini 3采用分层定价模式:
- 免费层:每月1000次请求,适合个人开发者和小型项目
- 专业层:每月10000次请求起,$0.002/次额外请求
- 企业层:定制化方案,包含专属支持和SLA保障
全球部署
模型已在全球多个区域部署,确保低延迟访问:
- 北美地区:us-central1, us-east1
- 欧洲地区:europe-west1, europe-west4
- 亚太地区:asia-southeast1, asia-northeast1
未来展望
Gemini 3的发布标志着多模态AI技术进入新的发展阶段。谷歌表示将继续投入研发,计划在2026年推出Gemini 4,重点提升模型的推理深度和创造性能力。
随着AI技术的不断进步,我们有理由相信,像Gemini 3这样的先进模型将在更多领域发挥重要作用,从科学研究到日常应用,为人类社会带来积极变革。